
《盛宣怀档案》智能分析系统的构建与史学应用——从检索增强到智能体推理
张光伟
摘 要: 面对浩如烟海且高度非结构化的历史档案,传统的数字化处理与关键词检索模式已难以满足日益复杂的史学研究需求,特别是在处理如《盛宣怀档案》这类涉及晚清政治、经济、外交等多维网络的复杂史料时,研究者常陷入查不全、理不清、关联难的困境。研究在回顾数字人文从数字化、结构化向智能化转型的技术背景的基础上,引入大语言模型前沿的思维链技术与推理—行动框架,构建了一个基于 Agentic RAG 的“盛宣怀档案智能分析系统”。该系统突破了传统知识图谱预定义的局限,通过“意图理解、资料检索、资料总结、评估决策、内容撰写”五个智能体的协同工作,实现了对全量档案文本的语义向量化与动态推理。系统具备主动规划检索路径、多步逻辑推演、跨文档证据互证以及自我纠错的能力,能够模拟历史学家“提出假设—史料搜集—考证辨析—形成结论”的认知过程。文章通过微观、中观和宏观三个层面的典型案例展示了该系统的应用潜力。研究实践证明,AI 时代这种“人机回环”(Human-in-the-loop)的协作模式,不仅能将历史学家从繁琐的信息搜寻中解放出来,更开启了以数字文献考古与全息逻辑增强为特征的历史研究新探索的可能性。
关键词: 盛宣怀档案;大语言模型;ReAct 框架;思维链;Agentic RAG;人机协作
作者简介:张光伟,陕西师范大学历史文化学院讲师,Email:zhangguangwei@snnu.edu.cn。
0 引言
历史学的数字化转型是一场漫长而深刻的长征。在过去的几十年中,这一进程大致经历了从文献资料的数字化、信息的结构化到知识的关联化三个阶段。以“中国历代人物传记资料库”(CBDB)为代表的基础设施建设,解决了史料可检索与可统计的基础问题,通过关系型数据库和知识图谱技术,让人文学者得以在大尺度上观察历史网络的演变。然而,这一阶段的数字人文往往被诟病为远读有余而深读不足——计算机擅长处理底层的、形式化的数据分析(如词频统计、社会网络中心度计算),却始终徘徊在人文研究的核心领地之外,难以触及意义阐释、因果推断与史料考证等需要高阶认知能力的人文专业端。
近年来,随着人工智能技术的爆发式突破,特别是以 ChatGPT、DeepSeek 为代表的生成式大语言模型(LLMs)的问世,科研范式正在发生根本性的转移。在自然科学领域, “AI for Science” 已经能够独立预测蛋白质结构、发现新材料,甚至在数学证明中展现出直觉般的推理能力;在社会科学领域,基于智能体(Agent)的生成式社会科学(Generative Social Science)正在模拟复杂的人类社会行为,重构我们对社会互动的理解。这种技术浪潮不可避免地席卷历史学领域,我们惊讶地发现,新一代 AI 不仅极大地扩展了能够处理的问题规模与复杂度,更在本质上缩小了计算技术与人文理解之间的语义鸿沟。
与传统的脚本编程或关键词检索不同,当前的大语言模型已经展现出了类似人类的思维链(Chain-of-Thought, CoT)能力。它不再仅仅是一个被动的数据提取工具,而是开始表现出模仿、甚至达到人文学者初级乃至中级科研水准的能力:它能够理解晦涩的古文语境,能够在多源异构的文本间建立逻辑关联,甚至能够针对某一历史假设进行初步的证据排查与证伪。
正是在这一技术与学术转型的关键节点,晚清史研究中的一座富矿——《盛宣怀档案》(以下简称“盛档”) ——为我们提供了一个绝佳的实验场。作为中国近代史研究中体量最大、内容最复杂的私人档案之一,盛档的内容涵盖政治、外交、实业、赈灾等晚清社会的方方面面。面对如此海量且非结构化的核心史料,传统的人力阅读难以胜任,而简单的关键词检索又往往面临“查不全”(异名同指问题)、“理不清”(事件线索交织)、“关联难”(跨文档证据断裂)的困境。
本研究旨在探索一种基于 AI 技术的新范式来破解上述难题。本研究进一步引入智能体与检索增强生成(RAG)技术,构建了“盛宣怀档案智能分析系统”。我们的研究实践表明,在 AI 时代,计算机可以从底层的数据搬运工晋升为历史学者的思维伙伴,通过人机协作实现对复杂历史问题的文献考古与逻辑推演。特别值得指出的是,我们此前倡导的“支架+管道”模式在 AI 的赋能下焕发了新生:它允许学者以低代码或零代码的方式构建研究工具,从而大幅降低技术准入门槛,让研究者能更专注于核心历史问题的探索,以期真正实现数字史学研究的提质增效。

1 从远读到智能体协作
随着人工智能技术的代际跃迁,数字人文的研究范式正经历着从数据驱动的宏观描述向逻辑驱动的智能推演的深刻转型。这一过程不仅是计算规模的扩大,更是促进人文问题解决模式质变的重要驱动力。
1.1 数字人文范式的演进与局限
在前大模型时代,数字人文的主流范式建立在弗朗哥·莫雷蒂(Franco Moretti)提出的远读理论之上。面对浩如烟海的文本,莫雷蒂主张放弃对单一文本的微观审视,转而通过计算机进行宏观的统计分析,以揭示那些肉眼不可见的文学形式与演变规律。这一路径催生了以米歇尔(J. B. Michel)等人的“文化组学”(Culturomics)和马修·乔克斯(Matthew Jockers)的宏观分析(Macroanalysis)为代表的量化史学实践。
在具体方法上,学者们广泛采用主题模型、社会网络分析和地理信息系统等工具,将非结构化的历史文本转化为结构化的数据图谱。然而,这种基于词袋模型(Bag-of-Words)和共现概率的传统范式存在如下显著的局限性。
(1) 语义语境的割裂:传统的定量方法往往将文本拆解为孤立的词汇或元数据,导致“只见森林,不见树木”,难以捕捉字里行间的隐喻、反讽及复杂的社会关系。
(2) 因果推断的缺失:泰德·安德伍德(Ted Underwood)曾指出,数字人文在描述 “发生了什么” 方面表现出色,但在解释 “为什么发生” 时往往力不从心。传统算法无法像历史学家一样,通过多源证据的比对来构建因果链条。
因此,在生成式AI快速发展的当下,数字人文应当从计算转向智能转型,探索智能增强(Intelligence Augmentation, IA)的路径,即利用 AI 作为认知延伸,辅助学者处理噪声并构建证据链,而非单纯的数据统计。
1.2 大模型推理框架:从思维链到自主智能体
生成式大语言模型的出现,为突破上述局限提供了技术可能。加西亚(Garcia )与 魏尔巴赫(Weilbach) 在其最新的研究中指出,大语言模型正在成为历史研究的有力助手,如果史料能够“说话”,模型便能辅助学者进行更高效的史料挖掘与分析。与基于统计概率预测下一个词的传统模型不同,新一代模型具备了更强的推理能力,使得计算机可能真的已经可以介入到历史考证的逻辑层面。以下我们对思维链、推理与行动(Reasoning and Acting,ReAct)框架和生成式智能体(Generative Agents)进行简要介绍。
(1)思维链。 Google Research 团队提出的思维链技术,通过在提示词中诱导模型生成一系列中间推理步骤(Intermediate Reasoning Steps),显著提升了其处理复杂逻辑任务的能力。在史学研究中,这意味着 AI 不再直接从史料跳跃到结论,而是能够像人类学者一样展示 “史料→考证→辨析→结论” 的完整思维过程。这种显式的推理路径不仅提高了准确率,更重要的是赋予了算法 “可解释性” 。
(2)推理与行动框架。单纯的思维链仍受限于模型内部的静态参数知识,容易产生“幻觉”。Yao 等人提出的推理与行动框架,将推理能力与外部工具的使用相结合。在该框架下,模型遵循“观察→ 推理→ 行动”的循环。例如,当需要考证盛档中书信提到的某个人的身份时,模型会先根据上下文比如提到的其担任的官职来思考“需要查询清代职官表”,然后执行检索行动,根据检索结果修正假设,直至得出确切结论。
(3)生成式智能体。在社会科学领域,帕克(Park)等人提出的生成式智能体理论 ,展示了 AI 模拟人类社会互动的潜力。智能体具备“记忆”“规划”和“反思”三大核心模块。在本系统中,我们借鉴这一理论,将 AI 设计为具备特定角色(如 “考据助手” )的智能体,它不仅能回答问题,还能根据历史学者的反馈记忆其偏好,并在多轮对话中动态调整研究策略。这意味着 AI 从被动的 “问答机器” 进化为具备自主性的 “研究伙伴”。
1.3 人机回环与交互模式的重构
随着技术能力的提升,人机交互的模式也从传统的“指令—执行”向“意图—对齐”演变。在处理高复杂度的历史问题时,完全的自动化既不可能也不可取,必须引入“人机回环”(Human-in-the-loop)机制。
(1)从“自动化”到“共驾” 。 传统的数字人文工作流往往是线性的:人清洗数据→机器跑算法→人解读结果。而在基于RAG 和智能体的新范式中,交互变成了迭代式的协作模式。AI 负责海量信息的初筛、逻辑链的构建和初步结论的生成(Drafting),历史学者则负责高阶的价值判断、逻辑漏洞的审查(Verifying)以及方向的纠偏(Refining)。
(2)人机回环的价值升华。 在本系统中,专家的反馈不再仅仅是纠错,而是系统进化的养料。通过记录学者对 AI 推理过程的修改,系统能够通过上下文学习或微调,不断“对齐”专业史学家的思维方式。这种人机协作不仅解决了 AI 的“幻觉”问题,也有机会反向激发学者的历史想象力,实现了本·施奈德曼( Ben Shneiderman)所倡导的“以人为本的 AI”,即在保持高水平自动化的同时,确保人类对研究过程的可控性与主体性。
2 基于Agentic RAG的多智能体协作架构
本系统的核心并非传统的静态数据库查询,而是一个基于代理增强检索(Agentic RAG)范式的动态推理系统。该系统直接基于全量档案文本,通过多智能体(Multi-Agent)的分工与协作,模拟历史学家“提出问题—史料搜集—考证辨析—形成结论”的认知过程。以下我们分层次介绍一下系统的架构。
2.1 以全量文本的语义向量化构建的数据层
鉴于盛档非结构化与碎片化的特征,我们采用标准 RAG的数据预处理流程。首先对档案数字化文本进行清洗与分段,保留书信的完整上下文结构。随后,利用 bge-m3 多语言嵌入模型将文本转化为高维语义向量,并存入 ChromaDB 向量数据库。这一过程将离散的史料映射为连续的语义空间,使得系统不仅能检索关键词,更能基于语义相似度召回隐含关联的史料(如将“杏荪”与“盛宣怀”在向量空间对齐),为后续的智能体推理提供数据基座。
2.2以多智能体协同与推理—行动闭环构建的逻辑层
系统的整体架构遵循“分层解耦、动态协作”的设计原则,自下而上分为数据基础设施层、多智能体协作层与交互层(如图 1所示)。其中,核心的“多智能体协作层”摒弃了传统的线性处理模式,而是采用基于DeepSeek-R1大模型的Agentic RAG架构。该架构包含五个专门功能的智能体,通过推理—行动闭环实现对复杂历史问题的迭代求解。
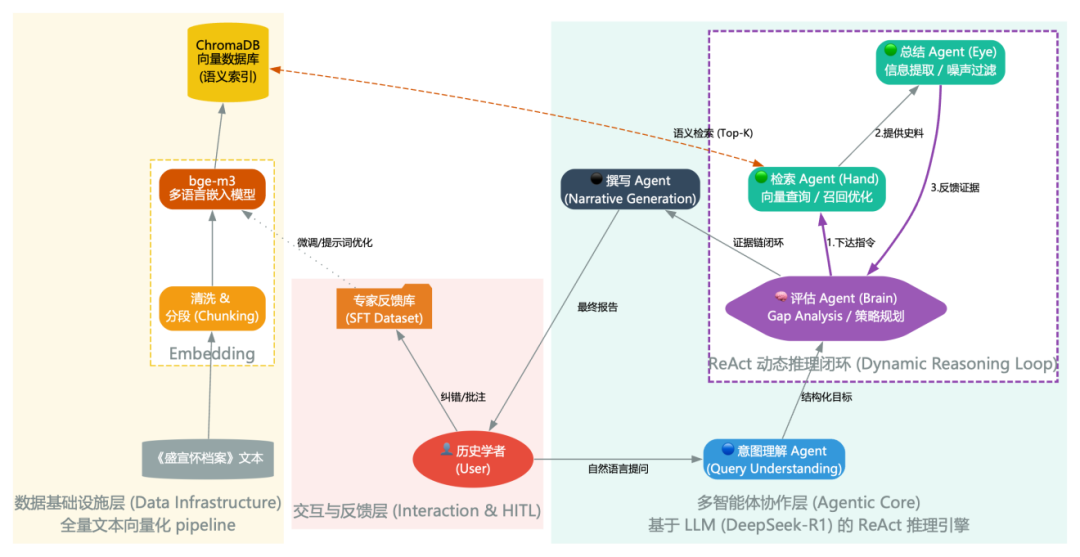
图1 系统整体架构图:基于Agentic RAG的多智能体协作
五类核心智能体的角色与权限分别为:
(1)用户意图理解智能体:作为系统的“前台”,负责解析用户的自然语言提问。它不仅进行关键词提取,更对问题背后的史学意图进行解构。例如,当用户询问“石帅是谁”时,该智能体会分析出这是一个“人物考证”任务,并识别出需要关注的时间与地点等约束条件,将其转化为初始的检索目标。
(2)资料检索智能体:作为系统的“手”,负责与数据层交互。它能够根据当前的检索目标生成多组查询向量,并在向量空间中召回若干(Top-K) 相关文档片段。
(3)资料总结智能体:作为系统的“眼”,负责阅读召回的史料片段。它不仅是对文本的简单摘要,而是基于当前问题的上下文,提取关键证据(如时间戳、官职、人际关系),并过滤掉无关的噪声信息。
(4)评估智能体:系统的“大脑”,这是实现推理—行动模式的关键。该 Agent 负责比对 “当前已获取的证据” 与 “解决问题所需证据” 之间的差距(Gap Analysis)。如果证据不足或存在矛盾(如 “石帅” 指向不明),它会制定下一轮的检索策略,指示检索智能体寻找新的线索。如果证据链闭环,它将向撰写 智能体发出终止信号。
(5)撰写智能体:作为系统的“笔”,在证据链完备后,依据史学规范撰写最终回答,并自动标注每一处结论所依据的[文献ID],确保学术严谨性。
2.3 工作流:模拟历史学家的迭代研究
上述智能体中,“(2)检索—(3)总结—(4)评估”构成了一个动态的推理—行动循环。这正是本系统区别于普通搜索工具的本质所在:第一轮,检索 智能体可能仅找到模糊线索;评估智能体发现初步结论与信件背景时间不符(Gap 发现),随即调整方向,即评估与迭代。第二轮,检索智能体根据新指令查询新的信息,召回更为准确的记录。多轮迭代后,系统利用提取的增量信息不断丰富上下文,直至逻辑自洽,即证据闭环。
这种逐步逼近真相的迭代过程,本质上是对人类历史学家研究方法论的计算模拟,其详细的工作流程如图2 所示。
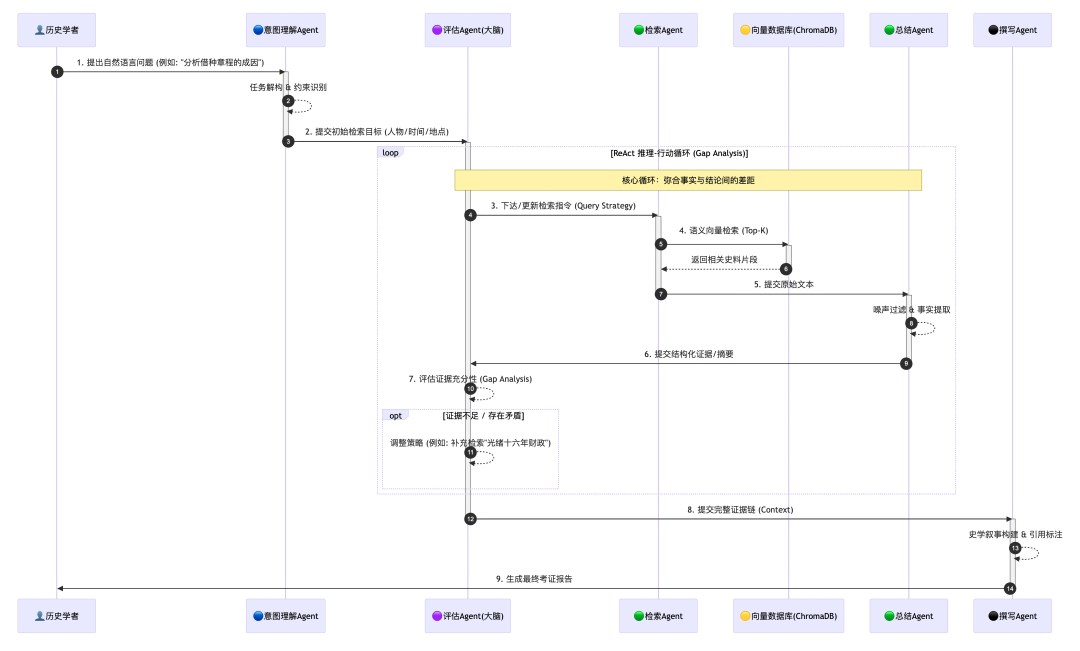
图 2 智能体在时间维度上的协作逻辑
3 史学应用实践:多维度的历史解析
通过对盛档的实际测试,本系统不仅验证了 Agentic RAG 架构在处理海量非结构化史料时的有效性,更在微观文本考证、中观制度复原和宏观风格分析三个层面展现了超越传统检索工具的研究智能。该系统所体现的智能体在多维度历史解析方面的能力如图3所示。
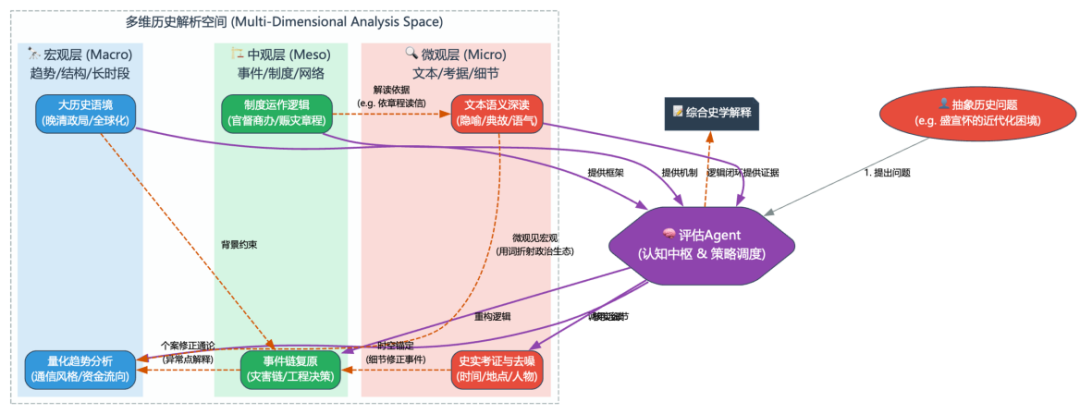
图3 智能体多维历史解析跃迁图
3.1 微观层面的反向纠错与多源批判性考证
在传统的数据库检索中,学者必须预知准确的关键词,且检索结果往往受限于用户提问的预设偏差。而在本系统的运行逻辑中,意图理解智能体与评估智能体协作,使其具备了对用户提问进行“事实核查”与“反向纠错”的能力。
我们设计了一个包含误导性前置条件的提问:“盛宣怀随李鸿章西征途中,给夫人写了不少家信,其中有一首诗,这是盛宣怀档案中仅见的诗作。这首诗的内容是什么?”
如果仅以关键词“诗”进行匹配,系统极易漏掉嵌在信函正文中的无标题诗句;如果盲从“仅见一首”的预设,算法可能会在找到第一条结果后停止检索,导致史实遗漏。这是传统检索难以解决的困境。
本系统的多智能体推理过程如下:(1)全量召回与质疑(检索智能体):系统并未被“仅见”这一约束限制,而是通过语义向量检索,遍历了所有包含韵文特征的家书片段,同时召回了《端午车中七律》([ID:sxh17-0038])、《庚午季夏潼津营次藁》([ID:sxh17-0026])和《六月八日寄内诗》([ID:sxh17-0041])。
(2)矛盾检测与修正(评估智能体):评估智能体 在对比检索结果与用户提问时,触发了 “证据冲突”警告 ——事实(三首)与预设(一首)不符。系统随即启动纠错机制,判定用户预设错误。
(3)深度语义解读(撰写智能体):在确认文本后,系统进一步分析了这些诗作的情感内核。它指出,盛宣怀引用“远别胜新婚”典故体现了儒家伦理下的夫妻责任,同时用“野店孤灯”“巫峡雨”等意象流露了个体在宏大历史叙事下的脆弱感。
这一案例证明,具备思维链能力的 AI 不再是盲从指令的工具,而是能够基于史料证据有一定独立判断能力的批判性读者。
3.2 中观层面的动态时空锚定与制度逻辑重构
在中观层面,历史研究往往涉及复杂的事件演进和制度变迁。面对碎片化的公文,系统通过推理—行动循环,展示了强大的跨文档关联与逻辑链重构能力。
面对一组关于“献县借种”“本道”以及“大户捐粮”的零散公文片段,我们要求系统解析其核心内容与历史逻辑。本系统通过三轮迭代,还原了被淹没的历史真相。
第一轮思考(时空锚定与去噪):虽然文本仅提及模糊的“同光时期”,但 总结智能体敏锐地抓取到一份下级禀帖中的收文日期“光绪十六年闰二月十一日”(1890 年)[文献 73607]。评估 Agent 以此为锚点,指示系统排除了内容相似但实际发生在 1906 年的《丙午桃源章程》[文献 41428],成功完成了高难度的“史料去噪”。
第二轮思考(政策比较与身份确证):系统对比文献 [1333] 与 [1334],识别出当时存在两种截然不同的救灾模式:沧州的“强制大户捐粮”与献县的“官府借贷+大户协调”(《借种章程》)。同时,检索 Agent 通过调用职官数据库,确证了文中自称的“本道”即时任清河道道员潘骏文[文献 16276],构建了“李鸿章(决策)—潘骏文(制定)—府县(执行)”的行政链条。
第三轮思考(Gap Analysis 与灾害链重构):这是最关键的一步迭代。评估 Agent 在分析财政数据时发现了一个 Gap(逻辑缺口):如果春季的《借种章程》有效,为何次年春抚支出高达 20 万两[文献 9242]?这暗示了秋收可能遭遇了新的危机。基于此 Gap,系统发起了新一轮针对“秋灾”的检索,成功发现了“黏虫伤损”与“运河决堤”的记录[文献 1413, 56297]。
最终结论:系统最终构建了 “春旱→政策响应(借种)→秋涝/虫害(次生灾害)→财政危机” 的完整因果链条,指出该案例并非单一赈灾事件,而是晚清基层治理试图通过制度创新应对复合型灾害的典型尝试,且李鸿章的“截漕发帑”[文献 74021]在高层提供了关键的财政兜底。
这一过程展示了 AI 如何像历史学家一样,利用异构史料进行三角互证,并通过识别逻辑断裂来驱动研究的深入。
3.3 宏观层面的全量文本的风格量化与“远读”
针对“李鸿章与盛宣怀通信风格演变”这一宏观问题,本系统利用其向量化数据库的优势,对 1876 — 1900 年两人之间的数十封书信进行了动态时段切分与量化分析。
资料总结 Agent 提取了每一封信中的称谓、自称及落款格式,生成了可视化的演变图谱。系统分析指出,二人的互动经历了从“萌芽期”(盛作为下属的请示)、“鼎盛期”(共谋洋务实业)到“转折期”(甲午后政治失势)的演变。在语言风格上,系统捕捉到了李鸿章对盛宣怀称呼的细微变化(从全称“杏孙世仁弟大人阁下”简化为“杏孙仁弟”),并揭示了一个深刻的政治隐喻:即便在盛宣怀权力上升、甚至在实业领域主导话语权后,他依然在书信中严格保持“犬马”、“废材”等自谦语态的伦理话语体系。这种基于全量文本的细粒度分析,为理解晚清幕府与官僚政治中实权与礼制的张力提供了新的量化视角。
4 讨论
本研究实践表明,当大语言模型被赋予 Agentic RAG 的架构与 ReAct 的推理能力后,它可能正在重塑我们对数字史学的理解,因为这不仅仅体现效率的提升,更体现了认知维度的扩展。
4.1 数字考古与全息逻辑重构
AI 时代的史学研究正在经历一场“数字考古”。传统的考古挖掘的是埋藏于地下的实物碎片,而我们现在利用 AI 挖掘的是沉睡在海量文本碎片中被淹没的逻辑连接。
与传统的关键词检索不同,本系统展示了一种 “全息逻辑重构” 的能力。在献县赈灾的案例中,系统并非简单提取“灾害”字眼,而是像一个老练的侦探,在微观的下级禀帖日期、中观的财政报销账册与宏观的督抚奏折之间反复“跃迁”。它通过 差异评估(Gap Analysis)机制,敏锐地捕捉到“春季借种”与“次年高额支出”之间的逻辑断裂,进而主动挖掘出被史料表象掩盖的“秋季洪涝”与“运河决堤”真相。这种从碎片中重建完整因果链条的过程,似乎在表明计算机真的可以介入到历史解释的核心环节。
4.2 动态时空锚定与异构史料的三角互证
历史研究的基石是考证,而考证的核心在于对时空坐标的精确锁定。本系统最显著的技术特征在于其基于评估智能体 的动态时空锚定能力。
在处理盛档案这类非结构化史料时,时间漂移(Time Drift) 是常见的陷阱(如将 1906 年的《桃源章程》误用于 1890 年的语境)。本系统突破了单一文档的限制,能够主动检索具有确切纪年的辅助文档(如收文日期、官员任免履历、年度财政报表)作为“锚点”,对模糊的文本进行校准。同时,系统实现了异构史料的三角互证——用人事档案(潘骏文的道员履历)验证公文作者,用财政档案(春抚银两支出)验证灾害后果,用气象记录(雨泽奏报)验证事件背景[22]。这种多源证据的交叉验证,极大地降低了 AI“幻觉”的风险,提升了机器考证的史学严谨性。
4.3 从工具到“对抗性伙伴”的认知升级
本系统的应用实践中,某种程度上体现了人机关系发生的变化。AI不再仅仅是唯命是从的检索工具,而是进化为具备批判性思维的 “对抗性伙伴”。
正如我们在诗作考证案例中所见,当用户提出带有误导性预设(“仅见一首”)的问题时,系统并没有顺从用户的认知偏差,而是基于全量数据的检索结果进行了 “反向纠错”。这表明,人机交互正在从单向的“指令—执行”转变为双向的“对话—博弈”。在这种模式下,AI 承担了海量信息的梳理与初级逻辑构建工作,使历史学者得以从繁琐的资料搜寻中解放出来,专注于提出更高质量的问题、进行价值判断与伦理审视。
5 结语
《盛宣怀档案》智能分析系统的构建与应用,是一次将前沿 AI 技术(Agentic RAG、ReAct 框架)与传统史学考证深度融合的实验性探索。它证明了通过搭建合理的智能体分工与知识库基座,大语言模型完全有能力突破远读的局限,在微观、中观与宏观三个维度上展现出模拟专业学者的研究能力。当然,AI 并非要取代历史学家,而是要成为历史学家手中的思想透镜。未来,随着专家反馈数据的持续注入与模型的不断微调,我们有理由相信,本研究所探索的人机回环协作模式,将有望帮助我们在浩瀚的史料海洋中,发现那些曾被遗忘的、更具解释力与洞察力的历史真相。
转载请注明“刊载于《数字人文研究》2026年第1期”;参考文献格式:张光伟.《盛宣怀档案》智能分析系统的构建与史学应用——从检索增强到智能体推理[J].数字人文研究,2026,6(01):43-52.全文PDF已在知网、万方及编辑部网站(http://dhr.ruc.edu.cn)上发表,此处注释及参考文献从略。
Views: 63